Random recommendation due to concurrency
This is the story of how a simple mitigation solution led us to discover the root cause of a difficult-to-replicate bug, originating from a lack of knowledge about a technology.
When I started in the Recommendation System team at Globo.com in 2014, there was already a system in production that was used to recommend other articles on the side of the article screen. It was initially used on only one of Globo.com’s sites and was about to be used on another one as well.
I don’t exactly remember which sites they were, but let’s say initially it was G1, a news website, and it was about to be adopted on GE, a sports website. It was at this moment of adoption that we started receiving sporadic complaints about GE articles being recommended on G1 and vice versa. This was a huge problem, there couldn’t be cross-recommendation between products at that moment, and the fact that this bug was occurring was a risk to the continuity of the recommendation systems project.
However, we were unable to consistently replicate the issue. Every now and then, someone on the team would be able to witness it, proving that yes, it was not just a hallucination.
To quickly mitigate the issue, we thought of a simple solution, but before explaining this solution, it is important to understand how the first version of recommendation on Globo.com worked.
There was an API written in Ruby, which in the request made by the client of the article, searched in a Mongo DB for the IDs of articles recommended to a user for a specific website. This personalized recommendation was generated in a periodic batch using Mahout on Hadoop. These article IDs were sent to a Solr Handler along with the ID of the context article where the recommendation would be presented. In this Solr handler, a More Like This query was executed to find similar articles to the context article, and these two lists of articles were then combined for the recommendation return. The diagram below demonstrates how each system interacts.
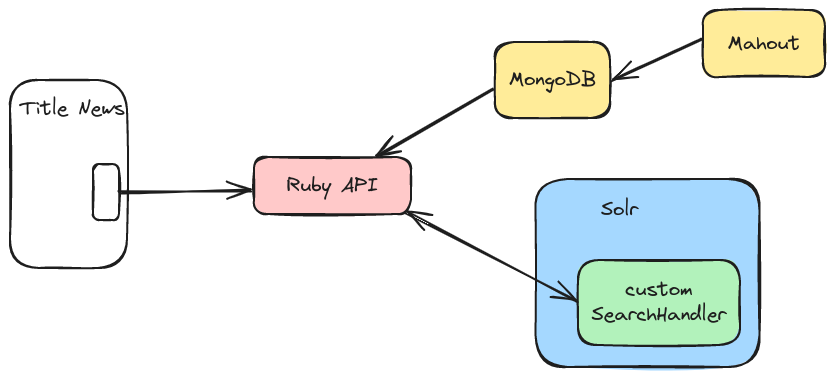
In other words, it was a mixture of personalized recommendation through collaborative filtering calculated by Mahout and contextual recommendation by similarity calculated by Solr. And the customized Solr Handler combined both lists.
Looking at the Solr Handler code, there didn’t seem to be any issue with the More Like This query that could cause a wrong return of articles from another site. Also, in the client we didn’t find any sign of a problem with sending the site ID incorrectly. In the Ruby API, also quite simple, there didn’t seem to be any issues with querying the Mongo DB with the site ID or passing this ID to the Solr Handler.
Then we were left with the calculation of the personalized recommendation, whose code was a little more complex to understand, involving several codes in PIG and some Map Reduces for Mahout use. But it didn’t make sense for that to be the problem, as the execution of this batch process took about two hours, and when the sporadic case occurred, we would look at the key related to the user/site on the Mongo DB and not find this inconsistency.
Without any tricks up our sleeve, we decided to implement the simple solution I mentioned: Strengthening the filtering in the Solr Handler so that after combining the two algorithms, no content from another website would be returned. The idea was to stop the bleeding, and then try to better understand the root of the problem.
The solution was deployed and during the deploy we paid more attention to the Solr logs and found sporadic errors in the use of the SimpleDateFormat class. This class was used in this Solr Handler to format the final result of the articles. Looking at the code, it was possible to notice a possible source for this specific problem and a clue of what could be happening to cause the original problem.
SimpleDateFormat is not threadsafe, so it is ideal not to use global instances. In this Solr Handler, SimpleDateFormat was not instantiated statically, which is a good sign. However, it was instantiated as an attribute of the class. This means that each instance of the Handler would have its own SimpleDateFormat. If each request instantiated its handler, we would not have the concurrency issue.
But we were having. Reading the documentation, it became clear that the Solr Handler was not generating an instance per request. So in practice, the SimpleDateFormat was being reused in several requests causing the sporadic errors we observed in the logs. Another attribute that was inadvertently in the same situation was the list of documents to be returned in the request.
Gotcha! That’s when you have finally caught the source of the problem!
During the request, when the combination of the return of More Like This occurred with the personalized recommendation sent via parameter, if another request occurred at the same time, the recommendations from different people and sites were combined.
It was possible to replicate the problem locally by adding sleeps to force slowness and then execute simultaneous requests. The final solution was to remove these instance attributes and only use them locally in the methods.
This demonstrates the importance of understanding the system in which you are working, especially when working with multi-threaded systems.
This reminded me of a problem in the past also at Globo.com, but in this case caused by me: I used a HashMap as cache in a multithread service, and this caused several locks in the application, for the same reason: HashMap is not thread safe. The problem was only identified with thread dumps and the solution was to use a ConcurrentHashMap instead.
Finally, the lesson is: There is no doubt that it is easier to learn by doing, but to put it into production, it is important to carefully read the specifications of the libraries, frameworks, and environments we are using. And in case of a difficult analysis problem, it is worth trying simple and potentially ineffective solutions, because that may lead you to a greater understanding of the real problem.